
AP计算机科学A复习:Unit 1 – Primitive Types 基本的数据类型
这是AP CSA课程的第一个单元,我们将了解Java编程中最基础的一些知识点,例如四则运算。与我们以往熟悉的手写算数式不同,计算机编程中还需要区分不同格式的数据,并且根据程序需要使用合适的数据格式,我们把这些数据格式称作「Data Types」。
在开始之前,建议你再次打开「概述篇」看到课程大纲对每个单元的简介。作为AP CSA课程的正式开始,我们要先了解它的内容结构。其中U1, U3, U4介绍的都是计算机编程最基础的语法,包括顺序结构,即从上往下依次执行的程序;选择结构,比如if语句,根据程序运行时的不同实际情况自动做出预设好的反应;循环结构,在满足预设的条件时,反复执行某些操作。而U2, U5则学习Java的「面向对象编程」特征,在这里我们将了解什么是「对象Object」;Object和Class和Methods等等看似抽象的名词应该如何理解 等等。随后的U5, U6, U7分别讲述数组、动态数组、和二维数组的语法和实际在程序写作中的应用。U9是Java语言的一大亮点,即「继承Inheritance」,已经在「概述篇」对应的单元简介展示过例子。U10则介绍了一种由Method自己调用自己以达到类似循环结构效果的算法。
所以,从我自己的感受看来,学习AP CSA课程的顺序应该是:
- U1-> U3-> U4
- U2-> U5
- U6->U7-> U8
- U9
- U10
U1.1 输出更多细节
在上篇U0的材料的U0.1中,我们已经知道了如何写作一个程序来把某些数据显示在计算机的输出设备——屏幕上。我们已经知道,输出语句的尾巴上有一个括号,这个括号里面的内容是表达式「expression」,而表达式就是我们要输出显示到屏幕上的内容。上篇材料还对比了用引号把表达式里的内容括起来,和不括起来有什么区别。所以你已经知道,输出一串文本内容时,应该使用引号把它括起来,这样计算机才知道你要输出的是一个字符串,而不是变量。相对的,如果直接在表达式里输入某个变量名且不加引号,输出的内容会是这个变量里面存储的数据,而不是变量名本身。
但你会发现,如果用的输出语句是下面这样,那么两个输出语句的内容会按顺序分别显示在不同的两行。也就是说第一个输出语句结束后提行了。
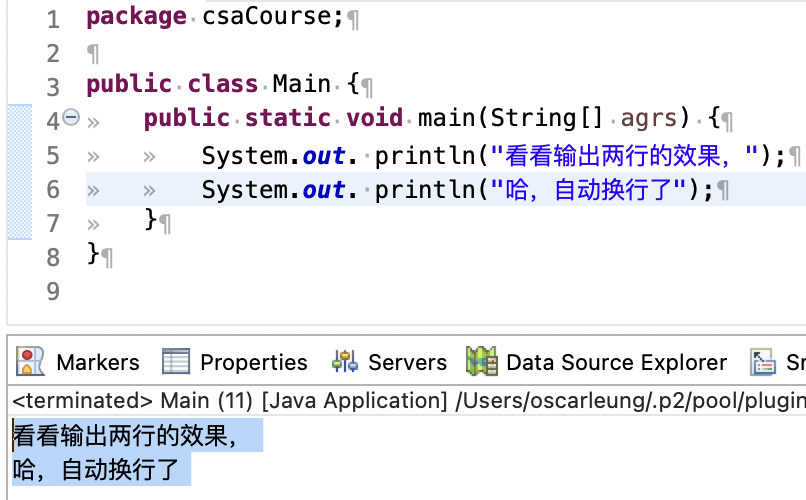
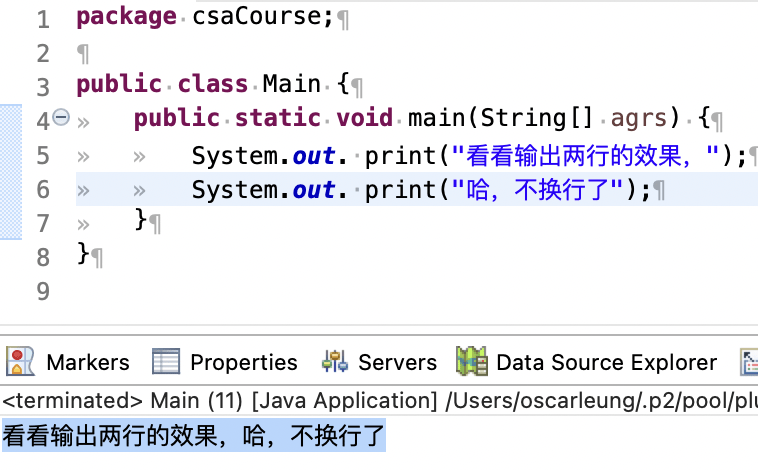
那如果我希望把两个输出语句的内容放在同一行呢,这个时候就需要对输出语句做出一点点超简单的修改。看到「println」,我们来拆解一下这个单词,「print」的意思是打印,它的后面紧跟的「ln」其实就是换行的指令。因此,我们写作输出语句的时候使用下面这样的写法,去除提行指令「ln」,就可以把两个输出语句的内容打印在同一行。
U1.2 Variables and data types
既然叫计算机,那么处理数据当然是比输出固定的文字更基本的功能。通过「声明变量」的方式,我们可以在计算机内存里开辟一块位置用来存放数据。在Java编程中数据被分为两大类,即「primitive types」和「reference types」。每一个被声明的「primitive types」变量都被存放在一块计算机内存中,可以视觉化的理解为每一个小格子就是一块内存,声明变量就是取一个小格子贴上名牌,同时规定这个格子具体的「data types」,不同格式的数据要存储在不同的「data types」里。例如,整数属于「int」,而小数属于「double」。一般不考察「reference types」的理论定义。
在AP CSA课程中我们会用到的具体的变量类型(而非大类)有「int」整数;「double」小数;「boolean」布尔变量;「String」字符串;「Array」数组。
我们可以简单的理解为「int」只能存储整数,「double」只能存带有小数点的数据,「boolean」是布尔数,只有两个可能性:「true」、「false」,分别代表「真」和「假」。后面的第3单元会有详细的介绍。「String」是字符串,顾名思义可以用来存储一段文字。「Array」比较特别,第六单元专门介绍「Array」的操作。
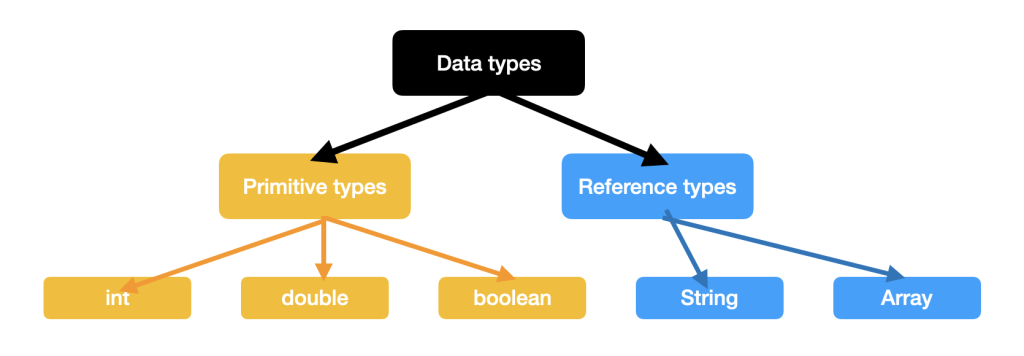
其中「int」、「double」、「boolean」属于「primitive types」;「String」、「Array」属于「reference types」。需要能够识别具体的变量类型属于哪一个大类。
然后是变量名称「variable name」,这相当于是一个门牌号,知道「variable name」就可以操作对应的格子里的数据。例如加减乘除。后文会具体介绍要用到的语法。
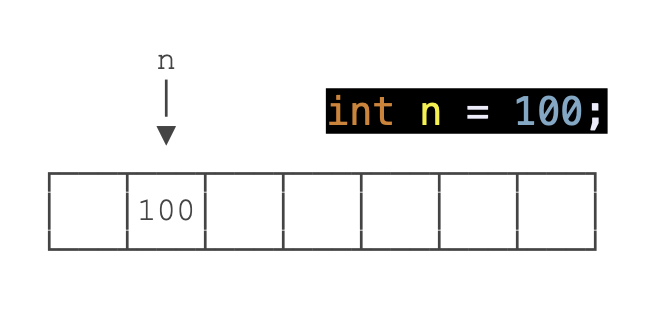
那么我们来尝试声明变量。声明变量的语句包含具体的「data type」,「variable name」。可以选择赋一个初始值,但也可以不这么做。如果选择赋初始值,使用「=」表示赋值,并在「=」后写上要放进这个变量里的初始值。记得在句子的末尾用「;」表示一句话已经结束。例如上图就是声明了一个用于存放整数数据的「int」变量,名字叫「n」,并且初始值为100。
然后,如果需要更新修改已经被声明的变量,就直接使用赋值符号「=」连接变量名「variable name」和新的值。例如,把上面声明的 n 变量重新赋值为233:
n = 233;这样就完成了变量的「变」,即再次赋值。
需要注意的是,我们已经知道要存储不同格式的数据格式需要声明不同「data types」的变量。也就是说,整数和小数即使表面上数值相等,也不能说是相同的,比如,1 ≠ 1.0 。
所以我们现在来尝试声明一个变量:开辟一个位置存放「小数」数据(记得,程序语句要写在method里面,而method必须存在于某个class之中)。把3.1415926存进去。点击下方折叠区域查看例子的解决方法。
学完变量,相对应就有常量。虽然我也没搞懂常量在Java编程中有什么存在的意义。从操作上来说,要声明一个常量,和声明变量的唯一区别是在声明语句的最开头加上「final」。常量和变量的区别是,常量一旦被声明就不可以被再次赋值(所以为什么不直接开个变量然后放着不动……)。我们举个例子。
package csaCourse;
public class Main {
public static void main(String[] agrs) {
final double pi = 3.1415926;
}
}这样,就可以声明一个常量。如果你尝试在后面给此处声明的「pi」常量再次赋值,就会报错。在自己的Eclipse里试试。
U1.3 Expressions and Assignment Statements 运算
学习了如何使用变量,或者常量,来存储数据之后,就可以开始了解简单的运算操作。在Java编程里,我们使用「+」代表加号,「-」代表减号,「*」代表乘号,「/」代表除号,「%」代表取模(也就是取一个除法的余数,小学数学~)。你可以选择直接在输出语句的表达式中写算式,这样可以直接输出这个算式的结果,不改变各个变量中的数据。比如下面这个例子:
int a = 3;
int b = 5;
System.out.print(a * b);输出的结果是15。但是变量a里仍然存储3,b里仍然存储5。
如果想要把运算的结果保存到变量中,你可以开一个新的变量,并在赋值符号后写上算式。这个方法和定义新变量并赋初始值在语法上没有区别,因此没有提供例子;另一种方法是,直接用参与运算的某个变量来存储运算结果。比如:
int a = 3;
int b = 5;
a = a+b;
System.out.print(a);此处的输出值为8,表示a变量存储的数据最终是8。因为在第三行的时候,a被重新赋值了最初的(a+b)的结果,(3+8) = 8,因此8替换了a里面原来的数据3。最终,第四行的输出语句访问变量a时,得到的数据是8。因此输出值为8。
运算时,注意使用合适的变量类型。如果两个整数进行运算,则结果一定是一个整数。如果两个数据中有任何一个「double」类型的小数,则结果一定为「double」类型的小数数据。我们看一个例子:
int a = 3;
int b = 2;
System.out.print(a/b);这个例子的输出结果是「1」,而不是正常人类期望的「1.5」。因为参与运算的两个数都是整数,因此结果的数据类型也是整数。整数的数据类型没有能力存储一个小数,因此「1.5」的小数部分被放弃,最终输出的数据是「1」。
但是,只要参与运算的两个数之中,有任何一个「double」类型的小数,则结果一定为「double」类型的小数数据。所以有了下面的这种情况:
double a = 3;
int b = 2;
System.out.print(a/b);这种情况下的输出值则是「1.5」。和上一个例子的区别是,我更改了变量a的类型。现在变量a是一个「double」类型的变量,因此在(a / b)的计算中将会得到一个「double」类型的运算结果。「double」类型的数据当然可以是一个小数,因此「1.5」被符合正常人类期望地输出了。
最后,我们补充一个细节。「+」在输出语句的表达式中可以用来作为计算符号,比如(a+b)这样的情况。但是当「+」被用于连接一个字符串和其他数据时,它的含义就变成了「连接」。因此我们可以用「+」在一个输出语句表达式中连接多个数据。比如:
int a = 3;
int b = 2;
System.out.print("a和b的数值是:"+a+b);输出的结果是「a和b的数值是:32」,因为这个表达式中含有字符串,因此「+」会被认为是连接符号。如果你希望在含有字符串的表达式中让「+」保留作为运算符号的功能,那就加上小括号,把(a+b)单独分隔开,方便电脑识别。这样做:
int a = 3;
int b = 2;
System.out.print("a加b的数值是:"+(a+b));所以输出结果会是「a加b的数值是:5」。
注意,如果使用整数除0会引发「ArithmeticException」错误,我们来观摩一下:
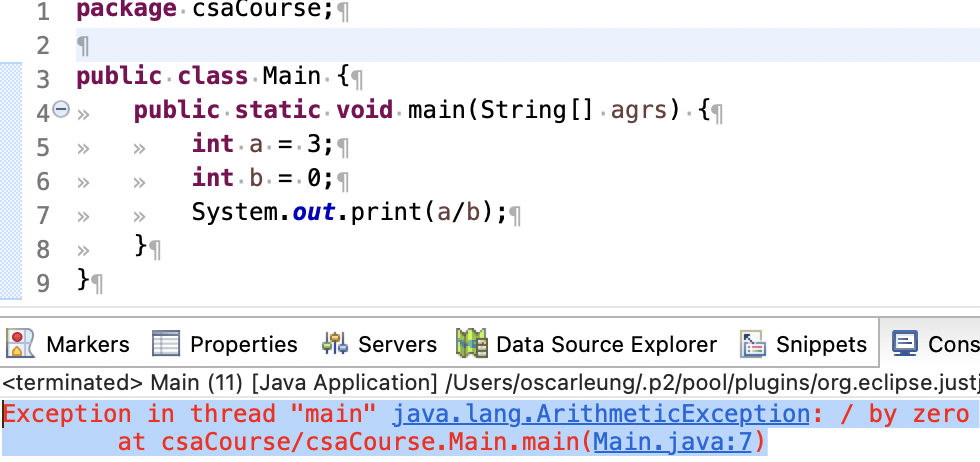
此处变量a是整数类型,因此用a中的数据除b就会导致「ArithmeticException」错误。至于拿一个「double」类型的数据除0会发生什么,在你的Eclipse尝试一下。
U1.4 Compound Assignment Operators 复合运算符
除了上面已经结束的基本的五个运算符号以外,Java还提供了复合运算符号用于简化运算式。它们是「+=」「−=」, 「*=」, 「/=」, 「%=」 。这些运算符号代表把一个变量里面的数据和另外的数据进行运算,再把运算结果存回这个变量。例如:
int a = 3;
int b = 6;
a *= b;
System.out.print(a);在这个例子中,「a *= b;」等效于「a = a * b;」。所以输出结果是18。记得在你的Eclipse尝试一下其他的复合运算符号。
除了以上的复合运算符号,还有两个特别的符号。他们是「++」increment 和「–」decrement(两个减号,这个地方打出来看不清)。他们分别代表递增1、递减1。比如「a++;」和「a = a + 1;」是相同的意思。
U1.5 Casting and Ranges of Variables
在U1.3我们提到,如果两个整数进行计算那么它们的结果是一个「int」整数类型的数据。因此运算(3/2)会导致正常人算出来的结果「1.5」丢失小数部分,因此存储的数据会变成「1」。这就是把「double」类型的数据强制转换为「int」类型的后果:丢失数据。但主动进行数据类型的强制转换是考纲的一部分,我们仍然要学习。这样写:
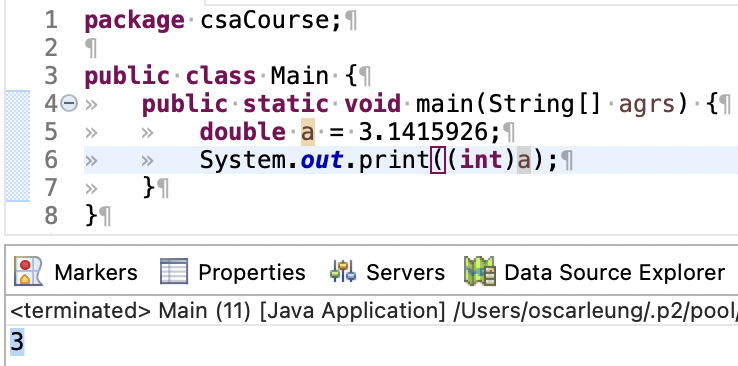
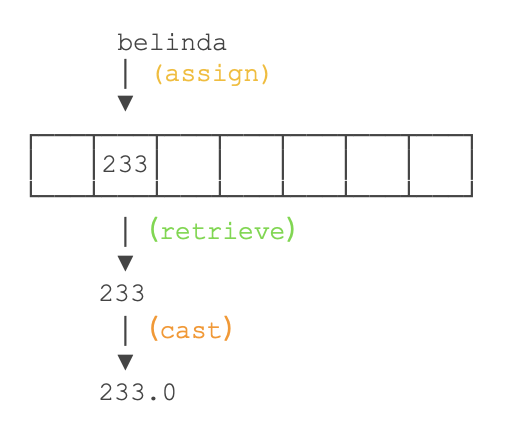
变量a 是一个小数,我们在输出语句的表达式中写上了a的变量名,但是在它之前加上了 (int)。这个用括号包起来的 int 就是强制转换数据类型的指令。因此,a在输出时被转换为整数,丢掉小数部分,输出3。注意:强制类型转换并不会改变原有变量的数据类型和数值,下图展示的是一个强制转换一个变量名为belinda的「int」类型的数据为「double」类型的逻辑演示。
既然强制把小数转为整数转换会是直接丢掉小数部分而非自动算出近似数,我们应该如何实现四舍五入呢?看下面程序的算法:
double a = 6.666;
double b = 2.33333;
System.out.println((int)(a+0.5));
System.out.println((int)(b+0.5));这个算法首先把小数类型的数据加上0.5,然后把运算结果的小数部分丢弃,得到四舍五入的近似数。例如 b 的原始数据是 2.33333,不足5所以要舍,加上0.5后是2.83333,此时强制转换数据类型丢掉小数部分则得到结果「2」。而 a 的原始数据是6.666,小数第一位已经大于5应该「入」,6.666+0.5 = 7.166,此时丢弃小数部分得到四舍五入结果「7」。
还需要注意的是,我们已经知道变量是被存放在内存里开辟的一块位置。这块位置的大小并不是无限的,而是根据不同变量类型,开辟对应的位置空间大小。如果要查询一个数据类型的存储空间最大值和最小值,用这些语句:
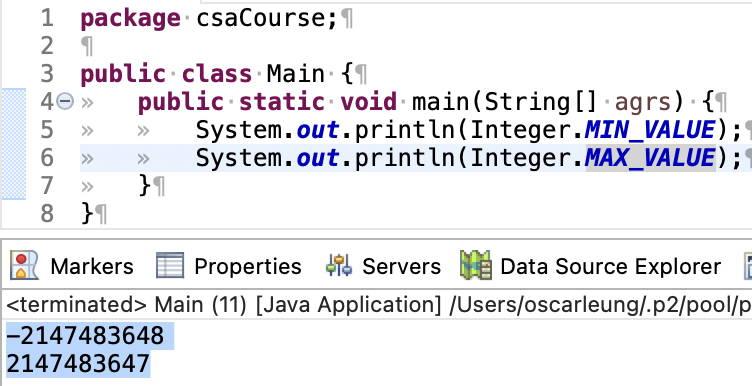
这里使用了「Integer.MIN_VALUE 」和「Integer.MAX_ VALUE」查询了整数类型「int」的最大和最小存贮能力。你也可以这个把这个语句中的Integer换成Double然后输出看看。如果在某个变量里存储了超过它的存储能力的数据,就会导致「overflow」,表现为存储的数据变成其它奇奇怪怪的内容。
总结
以上是U1的全部内容。我们完成了输出语句表达式的学习,并且了解了如何让计算机进行计算。各种运算符号可以组成不同的运算式。不同数据类型也可以相互转换……
练习
【交换 a 和 b】输入两个数a和b,交换他们在a与b里的位置,并输出。
【仿 · 学校作业】写一个Class,输入一个值作为半径。根据这个半径计算圆的面积、球的面积。π按3.14计算。输出得到的结果,以及对应的四舍五入近似数。
更新日志
2022 Sep 6 – 添加U1.2内容【重新给已经声明过的变量赋值】

发现一个问题,U1.2里面不应该说 1 ≠ 1.0 ,因为如果真的去判断 1 == 1.0 会得到true的结果。原文的意思是 1 的数据类型是「int」,「1.0」的数据类型是「double」,它们的性质不同。如果被用到运算式里,表现就是如果「int」类型的1和另一个「int」相互计算会得到一个同样是整数类型的结果;而1.0是作为「double」类型的数据和另外一个「int」类型的数据进行运算则会得到一个「double」类型的结果。